原文 Retrieval-Augmented Generation for Large Language Models: A Survey | PPT | 中文
在人工智慧和自然語言處理領域,生成式模型如 GPT-3 和 GPT-4 已經展示了強大的文本生成能力。然而,這些模型有時會產生不準確或不相關的回應。為了解決這些問題,檢索增強生成(Retrieval-Augmented Generation, RAG)技術應運而生。本文將介紹 RAG 技術的基本概念、運作原理及其應用。
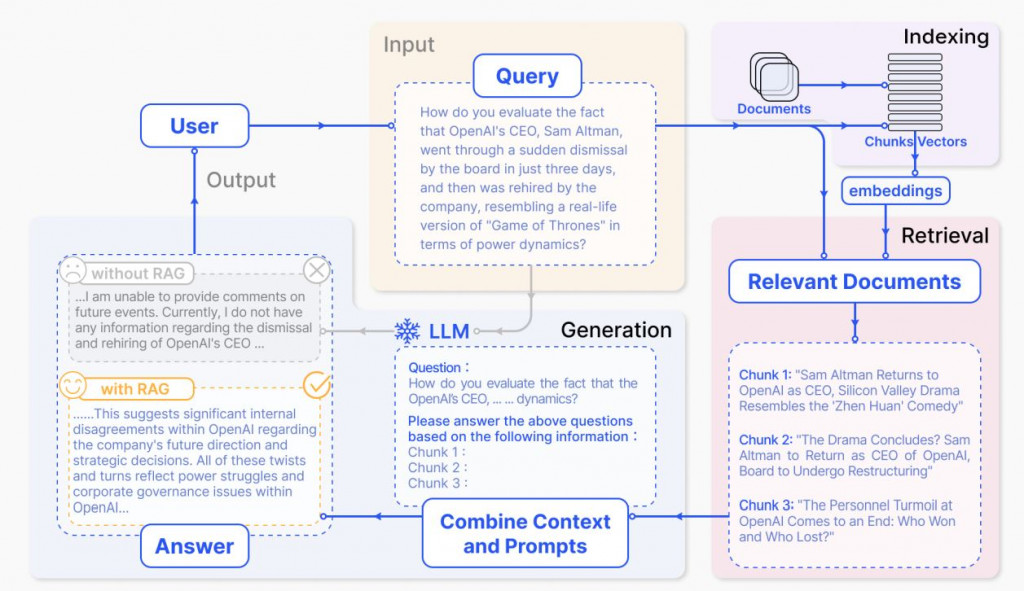
RAG 是一種結合預訓練大型語言模型與外部資料源的技術。這種方法結合了 GPT-3 或 GPT-4 等大型語言模型的生成能力與專門資料檢索機制的精確性,從而產生能夠提供細膩回應的系統。
 ref
ref
RAG 的運作可以分為以下幾個步驟:
資料收集:首先,收集應用所需的所有資料,例如用戶手冊、產品資料庫和常見問題解答列表。
本篇作者將RAG分為三種:Naive RAG、Advanced RAG、Modular RAG。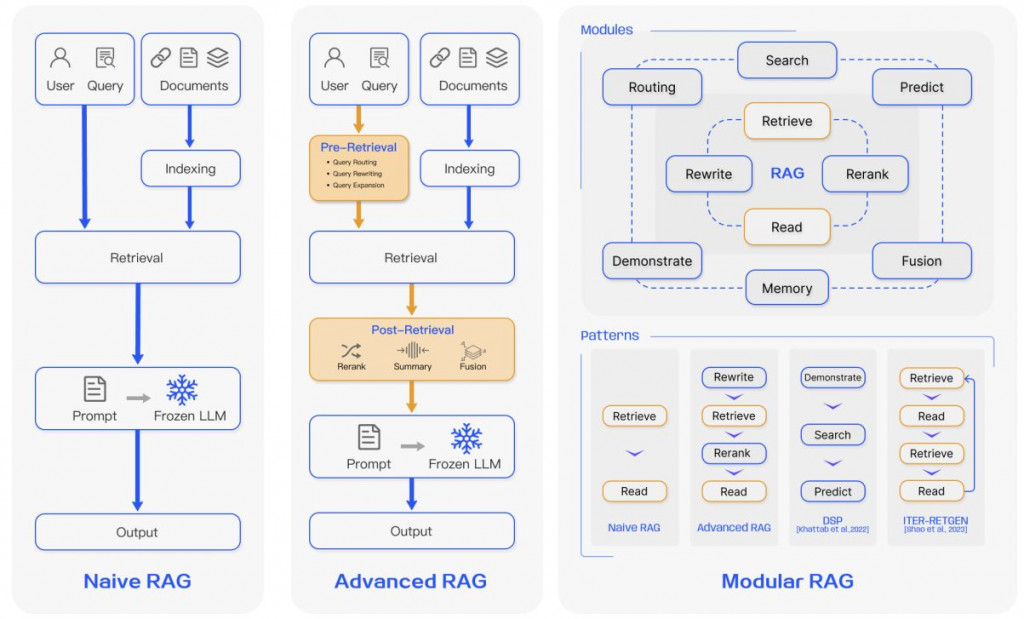 ref
ref
傳統的RAG包含了: Indexing ⮕ Retrieval ⮕ Genaration
補充:
Skip-Gram 和 CBOW 是用於 Word Embeddings 的技術,它們可以學習詞語之間的語義關係,並將詞語轉換成向量表示。這些向量表示可以作為語言模型的輸入,幫助語言模型理解詞語之間的關係。Skip-Gram 和 CBOW 可以被用於構建 RAG 中的語言模型,但並非 RAG 本身的一部分。 例如在訓練語言模型時,可以使用 Skip-Gram 或 CBOW 來生成詞嵌入,然後將這些詞嵌入作為語言模型的輸入。
簡而言之:
缺點: 檢索階段經常在precision和recall方面遇到困難,導致選擇錯位或不相關的區塊,並遺失關鍵資訊,生成困難。在產生回應時,模型可能會面臨幻覺問題,即產生檢索到的上下文不相符的內容。
Index Optimization ⮕ Pre-Retrieval Process ⮕ Retrieval⮕ Post-Retrieval Process ⮕ Genaration
在檢索之前,可以使用query改寫、routing 路由和 query擴展,讓模型改寫問題或是產生一個指導性的假文檔,然後將原始查詢與這個假文檔結合,形成一個新的query。
VectorDB / GraphDB
ReRank(重新排序):使用更高級的模型(如跨編碼器或多向量重排序器)對這些文檔進行重新排序,確保最相關的文檔排在前面。
Modular RAG 是一種將 Retrieval Augmented Generation (RAG) 系統分解成獨立模組的架構。每個模組負責特定的任務,例如信息檢索、文檔選擇、上下文編碼和文本生成。這種模組化的設計可以提高 RAG 系統的靈活性、可擴展性和可維護性。
RAG在問答系統中特別有用,如在醫療諮詢、法律咨詢、和教育領域。舉例來說,對於一個醫療問答系統,RAG可以從最新的醫學文獻中檢索信息,提供給醫生或患者最準確的建議。
儘管RAG技術在多個領域展現了其潛力,但仍然面臨一些挑戰。例如檢索和生成模型之間的協同效應需要進一步優化,以避免生成內容過度依賴某些檢索片段。此外如何處理多樣性和創造性與準確性之間的平衡,也是RAG技術未來需要解決的問題之一。
未來隨著更多資料的引入和模型架構的改進,RAG技術有望在更多應用中發揮作用,成為自然語言處理領域的重要工具。它不僅能夠提高生成文本的品質,還能促進知識更新,使人工智慧系統能夠更好地應對快速變化的世界。